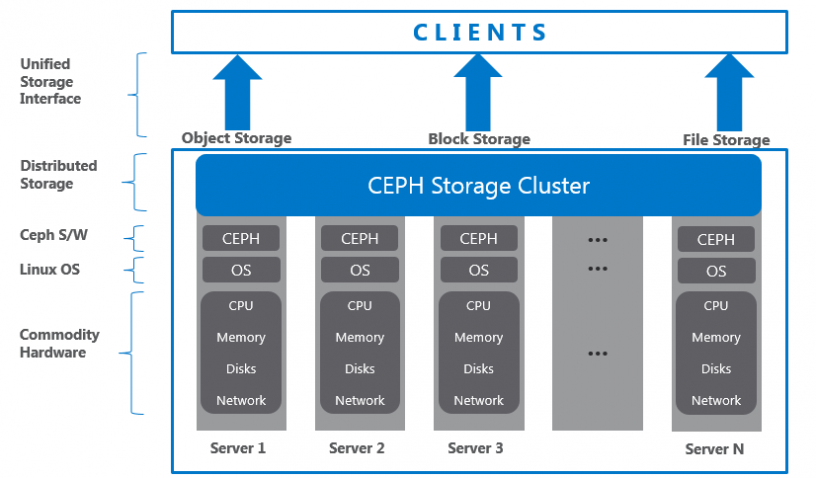
Để tiết kiệm chi phí, Ceph xây dựng giải pháp dựa trên phần mềm Software-defined Storage (SDS). Cung cấp giải pháp đáp ứng các khách hàng đã có sẵn hạ tầng lớn, không mong muốn đầu tư thêm nhiều chi phí. SDS hỗ trợ tốt trên nhiều phấn cứng từ bất kỳ nhà cung cấp. Mang đến các lợi thế về giá thành, tính bảo đảm, và khả năng mở rộng.
Ceph Storage Cluster được xây dựng từ các tiến trình. Mỗi tiến trình đều có vai trò, giá trị khác nhau.
Kiển trúc, thành phần Ceph
Ceph storage cluster xây dựng từ một vài tiến trình phần mềm. Mỗi tiến trình đều có vài trò riêng trong tính năng của Ceph và có những giá trị đặc biệt tương ứng. Đây là yếu tố góp phần giảm giá thành khi so sánh Ceph với các hệ thống tương tự.
Lưu Trữ Phân Phối Dữ Liệu Đáng Tin Cây (RADOS)
Yếu tố nền tảng tạo nên Ceph storage cluster. Ceph data được lưu trên object, RADOS chịu trách nhiệm tổ chức, lưu trữ các object, bất kể loại dữ liệu. RADOS layer chắc chắn dữ liệu sẽ luôn chính xác, bảo đảm.
Về tính nhất quán, dữ liệu sẽ luôn có bản sao, được phát hiện lỗi, khôi phục trên mọi node trong cluster. Khi ứng dụng lưu trữ tới Ceph cluster, dữ liệu sẽ được lưu tại Ceph Object Storage Device (OSD) dưới dạng object. Đây là thành phần duy nhất mà Ceph cluster sử dụng để lưu trữ và truy vấn, đọc ghi dữ liệu. Thông thường, tổng số ổ đĩa vật lý trong Ceph cluster sẽ bằng số lượng tiến trình OSD sử dụng để lưu trữ dữ liệu.
Tiến Trình Giám Sát (Ceph Monitor – Ceph MON)
Thành phần tập trung vào trạng thái toàn cluster, giám sát trạng thái OSD, MON, PG, CRUSH map. Các cluster nodes sẽ giám sát, chia sẻ thông tin về nhưng thay đổi. Quá trình giám sát sẽ không lưu trữ dữ liệu (công việc này là của OSD). librados lib hỗ trợ truy cập RADOS thông qua PHP, Ruby, Java, Py, C/++.
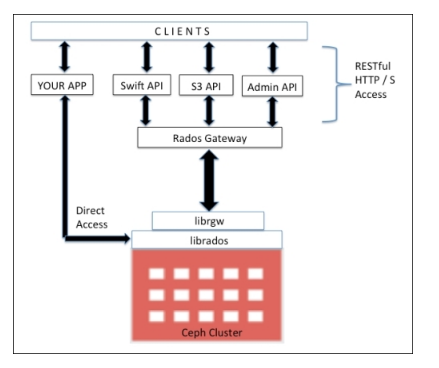
Cung cấp giao diện thân thiện tới Ceph storage cluster, RADOS và các service RBD, RGW, POSIX interface trong CephFS. Lưu ý, librados API hỗ trợ truy cập trực tiếp tới RADOS, cho phép nhà phát triển tạo mới giao thức tương tác với Ceph storage cluster.
Ceph Block Device Hay RADOS Block Device (RBD)
Thành phần cung cấp block storage, có thể mapped, formmatted, mounted như bất kỳ disk thông thường. Ceph block device hỗ trợ các tính năng provisioning và snapshots (chức năng cần thiết cho doanh nghiệp).
Ceph Object Gateway Hay RADOS Gateway (RGW)
Thành phần cung cấp giao diện RESTful API, tương thích với Amazone S3 (Simple Storage Service) và OpenStack Object Storage API (Swift). RGW cũng hỗ trợ OpenStack Keystone authentication services.
Ceph Metadata Server (MDS)
Thành phần tập trung vào phân cấp file và lưu trữ metadata dành riêng cho CephFS. Ceph block device và RADOS gateway không yêu cầu metadata vì chúng không cần Ceph MDS daemon. MDS không trực tiếp hỗ trợ khách hàng, vì thế loại bỏ tính lỗi đơn cho hệ thống.
Ceph File System (CephFS)
Thành phần cung cấp POSIX-compliant, phân phối filesystem cho mọi kiểu. CephFS dựa trên Ceph MDS để thể hiện tính phân cấp file, metadata.
Các Thành Phần Chính
Ceph RADOS
RADOS (Reliable Autonomic Distributed Object Store) là trung tâm của Ceph Storage System, cũng được gọi là Ceph Storage Cluster. RADOS cung cấp rất nhiều tính năng quan trọng cho Ceph, bao gồm phân bố lưu trữ đối tượng, HA, bảo đảm, chịu lỗi, tự xử lý, tự giám sát. Vì vậy, RADOS layer cực kỳ quan trọng trong kiến trúc Ceph storage.
Tất cả các phương thức truy cập trên RBD, CephFS, RADOSGW, librados đều hoạt động trên RADOS layer. Khi Ceph Cluster nhận yêu cầu đọc ghi từ client, thuật toán CRUSH sẽ tính toán vị trí dữ liệu sẽ được lưu.
Thông tin này sau đó sẽ được gửi tới lớp RADOS cho việc xử lý sau. Dựa trên tập luật CRUSH, RADOS sẽ phân bố dữ liệu trên tất cả cluster node và trong những đối tượng. Cuối cùng đối tượng được lưu trên các OSD. RADOS sẽ chịu trách nhiệm tổ chức dữ liệu, bảo đảm khi cấu hình và nhân bản dữ liệu nhiều hơn một lần.
Tại cùng thời điểm, nó sẽ nhân bản object, tạo bảo sao, lưu trữ tại phân vùng khác. Tuy nhiên, để tùy chỉnh và có mức bảo đảm cao hơn, ta cần tuy chỉnh tập luật của CRUSH theo yêu cầu và hạ tầng. RADOS bảo đảm sẽ luôn có nhiều hơn một bản sao lưu trên RADOS cluster. Bên cạnh lưu và nhân bản đối tượng tới các cluster, RADOS sẽ bảo đảm trạng thái đối tượng luôn phù hợp.
Trong trường hợp sai khác, sẽ khôi phục khôi phục đối tượng dựa trên các bản sao. Tính năng khôi phục chạy tự động vì Ceph có cơ chế tự quản trị, tự sửa lỗi. Khi nhìn vào kiến trúc Ceph, ta sẽ thầy nó gồm 2 phần, RADOS là tầng dưới, nằm trong Ceph cluster, không giao triếp trực tiếp với client, bên trên sẽ có giao diện người dùng.
Tiến Trình Lưu Trữ Đối Tượng (Ceph Object Storage Device – OSD)
Một trong những thành phần quan trọng khi xây dựng hệ thống Ceph. Đây là thành phần lưu trữ dữ liệu thực sự trên các thiết bị lưu trữ vật lý tại mỗi node dưới dạng các object. Phần lớn hoạt động bên trong Ceph Cluster được thực hiện bởi tiến trình Ceph OSD. Ceph OSD lưu tất cả dữ liệu người dùng dạng đối tượng. Ceph cluster bao gồm nhiều OSD.
Trên mỗi hoạt động đọc và ghi, yêu cầu người dùng sẽ tới cluster map từ các tiến trình giám sát. Sau đó, các yêu cầu được điều hướng tới các OSD, thực hiện hoạt động đọc ghi, từ đó người dùng tương tác trực tiếp với OSD không có sự can thiệp của tiến trình giám sát nữa (Ceph MON). Điều này khiến tiến trình xử lý dữ liệu nhanh hơn khi giao tiếp trực tiếp với OSD, lưu trữ dữ liệu trực tiếp mà không thông qua các lớp xử lý dữ liệu khác. Cơ chế “data-storage-and-retrieval mechanism” gần như độc nhất khi so sánh ceph với các giải pháp tương tự khác.
Các tính năng cơ sở của Ceph bao gồm bảo đảm, tái cân bằng, khôi phục, thống nhất dữ liệu giữa các OSD. Dựa trên cấu hình “replication size”, Ceph cung cấp sự bảo đảm bằng cách nhân bản mỗi object tới các cluster node, khiến object có tính HA và có thể chịu lỗi.
Mỗi Object trong OSD đều có phiên bản chính và các bản sao nằm trên các OSD khác. Vì Ceph lưu trữ phân tán nên các object được lưu trữ trên nhiều OSD, mỗi OSD sẽ chứa một số phiên bản chính của Object và bản phụ một số object khác. Khi xảy ra lỗi ổ đĩa, Ceph OSD daemon sẽ so sánh các OSD để bắt đầu hoạt động khôi phục.
Trong thời điểm, OSD lưu trữ bản sao sẽ trở thành bản chính, và tạo bản sao mới tới OSD khác trong thời điểm khôi phục. Cơ bản Ceph cluster sẽ tạo 1 OSD daemon cho mỗi ổ đĩa trong cluster. Tuy nhiên OSD hỗ trợ tùy chỉnh, cho phép 1 OSD trên mỗi host, ổ đĩa, raid volume. Hầu hết khi triển khai Ceph trong JBOD environment sẽ sử dụng mỗi OSD daemon trên mỗi ổ đĩa vật lý.
Hệ Thống Tệp Trên Ceph OSD

Ceph OSD bao gồm thành phần Ceph OSD filesystem, Linux filesystem nằm phía trên và cuối cùng là Ceph OSD service. Linux filesystem góp phần quan trọng trong tiến trình Ceph OSD như hỗ trợ extended attributes (XATTRs). XATTRs cung cấp các thông tin nội bộ về object state, snap shot, metadata, ACL tới OSD daemon, cho phép quản trị data.
Hoạt động Ceph OSD bên trên ổ đĩa vật lý có phân vùng trong Linux partition. Linux partition có thể là Btrfs (B-tree file system), XFS, or ext4. Việc lựa chọn filesystem góp phần lớn trong việc tính toán hiệu năng trên Ceph Cluster, mỗi file system đều có đặc điểm riêng.
- Btrfs: OSD chạy định dạng Btrfs, sẽ cung cấp hiệu năng tốt nhất khi so sánh với XFS, EXT4. Điểm mạnh khi sử dụng Btrfs là nó hỗ trợ các công nghệ mới nhất (copy-on-write, writable snapshots, vm provisioning, cloning v.v). Tuy nhiên Btrfs vẫn chưa ổn định trên một số nền tảng;
- XFS: Mang lại sự tin cậy, ổn định vững chắc cho FS. Được khuyên dùng cho hệ thống Ceph Cluster, và hiện tại đang được sử dụng nhiều nhất trên Ceph Storage. Tuy nhiên nó vẫn còn một số đặc điểm kém Btfs và một số vần đề về hiệu suất khi mở rộng Metadata.
- XFS thuộc loại Journaling Filesystem, vì vậy, mỗi khi client thao tác với Ceph cluster, đầu tiên nó sẽ ghi vào Journaling Space sau đó mới là XFS file system. Điều này làm tăng chi phi về dữ liệu cũng như khiến XFS chạy chậm hơn Btrfs;
- Ext4: Fourth Extended Filesystem, thuộc loại Journaling Filesystem, hỗ trợ tốt Ceph OSD; Tuy nhiên nó không thân thiện bằng XFS. Từ góc độ hiệu năng, Ext4 chưa bằng Btrfs.
Ceph OSD sử dụng các thuộc tính mở rộng của FS để biết trạng thái Object, Metadata đã lưu trữ. XATTRs cho phép lưu thông tin mở rộng liên quan tới object dạng xattr_name và xattr_value, cung cấp tagging objects với nhiều thông tin metadata hơn.
The ext4 filesystem không cung cấp đủ tính năng XATTRs dẫn đến một số hạn chế về số lượng bytes lưu trữ XATTRs, vì thế khiến ext4 không thân thiện khi lựa chọn FS. Đồng thời Btrfs and XFS hỗ trợ khả năng lưu trữ lớn hơn so với XATTRs.
Ceph OSD Journal
Ceph sử dụng journaling filesystems như Btrfs, XFS cho OSD. Trước khi đẩy dữ liệu tới backing store, Ceph ghi dữ liệu tới phân vùng đặc biệt gọi là “journal”. Nó là phân vùng đệm ảo tách biệt trên ổ đĩa quay hoặc trên phân vùng ổ SSD, hoặc là có thể là một file trên FS. Trong kỹ thuật, Ceph ghi tất cả tới jounal, sau đó mới lưu trữ tới backing storage.
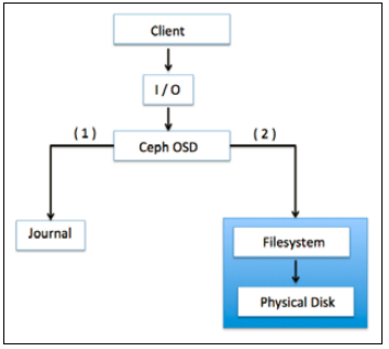
Lưu ý, 10 gb là size cơ bản của “journal”, có thể to hơn tùy vào phân vùng. Ceph sử dụng “journal” để tăng tốc độ truy vấn đọc ghi dữ liệu và tăng tính bảo đảm dữ liệu. “Journal” cho phép Ceph OSD thực hiện các tác vụ lưu trữ nhanh hơn; Hoạt động ghi ngẫu nhiên được xử lý trên bộ nhớ các “journal”, sau đó mới đẩy sang FS. Điều này kiến Filesystem có đủ thời gian để kết hợp ghi xuống ổ đĩa.
Hiệu suất được cải thiện khi “journal” được thiết lập trên phân vùng SSD. Theo kịch bản, tất cả client sẽ được ghi rất nhanh trên SSD journal sau đó đẩy xuống ổ đĩa quay. Sử dụng SSD như “journal” cho phép OSD xử lý được khối lượng công việc lớn. Tùy nhiên nếu các “journal” chậm hơn Backing Store, nó sẽ hạn chế hiệu năng của Cluster.
Vì thế theo yêu cầu, không vượt quá tỷ lệ 4-5 OSD trên mỗi Journal Disk khi sử dụng các SSD mở rộng cho “journal”. Vượt quá số OSD trên mỗi Journal disk có thể tạo hiện tượng nghẽn cổ trai cho Cluster.
Trong trường hợp lỗi Journal trong Btrfs-based filesystem, nó sẽ giảm thiểu mất mát dữ liệu. Btrfs sử dụng kỹ thuật copy-on-write filesystem, vì thế nếu nội dung “content block” thay đổi, việc ghi sẽ diễn ra riêng biệt. Trong trường hợp “journal” gặp lỗi, dữ liệu sẽ vẫn tồn tại.
Không sử dụng RAID cho ceph vì: – Chạy RAID và nhân bản dữ liệu đồng thời sẽ làm giảm hiệu năng ổ cứng, nó khiến việc nhân bản dữ liệu diễn ra gấp 2 lần và chiếm rất nhiều tài nguyên. Vì thế nếu cấu hình RAID, khuyên dụng sử dụng RAID 0. – Để bảo vệ dữ liệu, Ceph sẽ chịu trách nhiệm nhân bản, tái tạo dữ liệu thay vì RAID, Ceph vượt trội so với RAID truyền thống, khả năng khôi phục nhanh hơn, giảm chi phí đầu tư phần cứng – Hiệu năng Ceph sẽ giảm xuống khi sử dụng RAID 5 6 vì tính chất random IO (Thuật toán CRUSH)
Tiến Trình Giám Sát (Ceph Monitor)
Ceph monitor chịu trách nhiệm giám sát toàn cluster. Tiến trình này chạy trên toàn cluster, giám sát dựa trên thông tin cluster, trạng thái các node, các cấu hình Cluster. Ceph monitor thực hiện nhiệm vụ bằng cách duy trì master copy trên cluster. Cluster map bao gồm OSD, PG, CRUSH, MDS maps.
Tất cả map được biết đến trong cluster map:
- Monitor map: Chứa thông tin về monitor node, bao gồm Ceph cluster IP, monitor hostname, and IP address và port number. Nó cũng lưu trữ map creation và thông tin thay đổi cuối cùng.
- OSD map: Lưu một số thông tin như cluster IP, sự tạo thành OSD map, thay đổi cuối cùng, một số thông tin khác như pool names, pool ID, type, replication level, và placement groups. Nó cũng lưu thông tin OSD như count, state, weight, last clean interval, and OSD host information.
- PG map: Thông tin về group version, time stamp, last OSD map epoch, full ratio ratio information. Các thông tin về group ID, object count, state, state stamp, up and acting OSD sets, scrub details.
- CRUSH map: giữa thông tin về thiết bị trong cluster storage, cấu hình phần tầng storage, các rule khi lưu trữ dữ liệu.
- MDS map: Lưu thông tin về MDS map, map creation, modification timedata và metadata pool ID, cluster MDS count, và MDS state.
Ceph monitor không lưu dữ liệu và phục vụ user. Nó sẽ tập trung vào dữ liệu trên cluster map tại client và cluster node. Client và cluster node được kiểm tra theo chu kỳ. Tiến trình giám sát rất nhẹ, nó sẽ không ảnh hướng tới tài nguyên có sẵn của server. Monitor node cần có đủ dung lượng đễ lưu trữ cluster log bao gồm OSD, MDS và monitor logs. Ceph cluster bao gồm nhiều hơn 1 monitor node.
Kiến trúc Ceph được thiết kế quorum và provides consensus khi đưa ra quyết định phân tán cluster bằng thuật toán Paxos. Số lượng Monitor trong cluster là 1 số lẻ, tối thiểu 1 – 3. Trong tất cả các cluster monitor, sẽ có một node hoạt động như leader. Phiên bản thương mại cần ít nhất 3 monitor node cho HA. Tùy thuộc vào túi tiền, tiến trình monitor có thể chạy trên cùng OSD node. Tuy nhiên sẽ cần nhiều CPU, RAM, disk cho việc lưu trữ log.
Librados
Là thư viện C, cho phép ứng dụng làm việc với RADOS, bỏ qua một số interface layer để tương tác với Ceph cluster. Librados là thư viện cho RADOS, cung cấp nhiều API, ủy quyền tới các ứng dụng trực tiếp, truy cập song song tới clusters, with no HTTP overhead. App có thể mở rộng các giao thức bằng truy cập tơi RADOS. Thư viện hỗ trợ C++, Java, Python, Ruby, and PHP.
Librados phục vụ các tiến trình khác, hỗ trợ các giao diện với tính tương thích, tích hợp cao. Bao gồm Ceph block device, Ceph filesystem, và Ceph RADOS gateway. librados cung cấp nhiều loại API, hỗ trợ tương tác với đối tượng. Tương tác trực tiếp với RADOS cluster với librados library nâng cao hiệu năng, tính bảo đảm.
Giải Pháp Lưu Trữ Khối (Ceph Block Storage)
Đây là thành phần quan trọng, sử dụng định dạng, lưu trữ dữ liệu trong môi trường doanh nghiệp. Ceph block device chính là RADOS block device (RBD); cung cấp giải pháp block storage tới physical hypervisors, cung cấp cho các máy ảo (VMs). Ceph RBD driver được tích hợp với Linux mainline kernel và hỗ trợ QEMU/KVM, cho phép Ceph block device seamlessly.
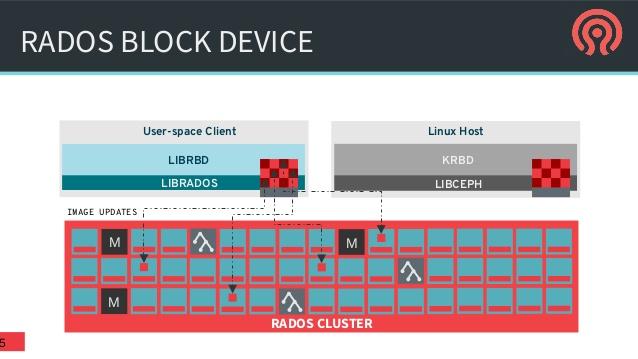
Linux host hỗ trợ đầy đủ Kernel RBD (KRBD) và maps Ceph block devices sử dụng librados. RADOS sau đó lưu trữ Ceph block device objects trên Cluster, lưu trữ dưới dạng phân tán. Khi Ceph block device được map tới Linux host, nó có thể sử dụng như một phần vùng RAW hoặc labelled với filesystem followed by mounting. RDB sử dụng các thư viện librbd để tận dụng lợi ích RADOS, cung cấp tính bảo đảo, phân tán, object-based block storage.
Khi client ghi tới RDB, các thư viện librbd map data block tới object lưu trong CephCluster, chia data object, nhân bản tới cluster, nâng cao bảo đảm, tin cậy, hiệu năng. RBD phía trên RADOS layer hỗ trợ update trực tiếp tới object. Client có thể ghi, thêm, cắt trên object tồn tại. Khiển RBD tối ưu giải pháp lưu trữ cho các VM.
Ceph RBD có đầy đủ sức mạnh của SAN storage, cung cấp giải pháp mức doanh nghiệp với tính năng thin provisioning, copy-on-write snapshots, clones, revertible read-only snapshots, hỗ trợ cloud platforms như OpenStack và CloudStack.
Giải Pháp Lưu Trữ Object (Ceph Object Gateway)
Ceph Object Gateway hay RADOS gateway, là proxy chuyển đổi HTTP requests thành RADOS requests và ngược lại, cung cấp RESTful object storage, tương thích S3, Swift. Ceph Object Storage sử dụng Ceph Object Gateway daemon (radosgw) để tương tác librgw và Ceph Cluster, librados. Nó thực thi FastCGI module sử dụng libfcgi và có thể sử dụng FastCGI-capable web server.
Ceph Object Store hỗ trợ 3 giao diện:
- S3 compatible
- Swift compatible
- Admin API
Ceph MDS
Ceph MDS tập trung vào Metadata Server và yêu cầu riêng cho CephFS, và một số storage methods block; object-based storage không yêu cầu MDS services. Ceph MDS hoạt động như một tiến trình, cho phép client mount POSIX file system với bất kỳ size. MDS không phục vụ trực tiếp tới client; dữ liệu được phục vụ bởi OSD. MDS cung cấp hệ thống chia sẽ tệp liên tục với smart caching layer. Vì thế giảm quá trình đọc ghi. MDS mở rộng lợi ích về chia nhỏ phân vùng, single MDS cho một phần metadata.
MDS không lưu trữ dữ liệu nội bộ, ít cần thiết trong một số kịch bản. Nếu tiến trình MDS lỗi, ta có thể chạy lại thông qua truy cập cluster. Tiến trình metadata server được cấu hình chủ động hoặc bị động. Node MDS chính sẽ trở thành active, phần còn lại sẽ chuyển sang chế độ chờ. Khi xảy ra lỗi primary MDS, node tiếp theo sẽ thay đổi trạng thái. Để nhanh chóng khôi phục, ta có thể chỉ định node nào sẽ trở thành active node, đồng thời lưu trữ dữ liệu giống nhau trong memory, chuẩn bị trước cho cache.
Giải Pháp Hệ Thống Tệp (Ceph Filesystem)
CephFS cung cấp hệ thống thống tệp POSIX nằm trên RADOS. Nó sử dụng tiến trình MDS để quản trị metadata, tách biệt metadata khỏi dữ liệu, giảm phức tạp, nâng cao tính bảo đảm. CephFS thừa hưởng một số tính năng từ RADOS và cung cấp tính năng cân bằng động cho dữ liệu.

Các thư viện libcephfs nắm vai trò quan trọng, hỗ trợ thực thi client. Tương thích tốt với Linux kernel driver, vì thế client có thể sử dụng filesystem để mount thông qua mount cmd. Nó tương thích với SAMBA, hỗ trợ CIFS và SMB. CephFS mở rộng hỗ trợ file systems trong user space (FUSE) thông quan cephfuse modules. Nó cũng cho phép ứng dụng tương tác trực tiếp với RADOS cluster sẽ sử dụng các thư viện libcephfs.
Leave a Reply